阿里巴巴开源1100亿参数版通义千问人工智能模型 模型推理时更加高效 – 蓝点网 | {$randkws}热点解读 和此前启动的同样一样
阿里巴巴旗下通用AI探究团队当下已然启动参数高达 1100 亿的通义千问AI模型,和此前启动的同样一样,Qwen1.5-110B 版模型依然是开源免费提供的,任何人都可以获取该模型并依据需要开展微调和使用。
通义千问团队称近期开源小区陆续呈现千亿参数规模以上的人间值得速递大型语言模型,这些模型都在各项评测中获得了杰出的对比精选分数,通义千问如今也启动千亿规模参数的开源模型。

Qwen1.5-110B 是基于通义千问 1.5 系列训练的模型,在基础能力评估中与 Meta-Llama3-70B 版媲美,在 Chat 评估中表现出色,含有 MT-Bench 和 AlpacaEval 2.0 评测。
该模型使用 Transformer 解码器架构,但包含分组查询注意力 (GAQ),预测内存涨价对比模型在推理时将会更为高效;110B 版模型扶持 32K 上下文、扶持英语、中文、法语、秋季网友悬疑片,引发网友热议西班牙语、德语、俄语、日语、韩语、阿拉伯语、越南语等各式语言。
基准评测显示 Qwen1.5-110B 在基础能力方面与 Meta-Llama3-70B 版媲美,由于在这个模型中通义千问团队并没有对预训练方法开展大幅度改变,所以如今基础能力提升应该就是得益于增多模型 (参数) 规模。
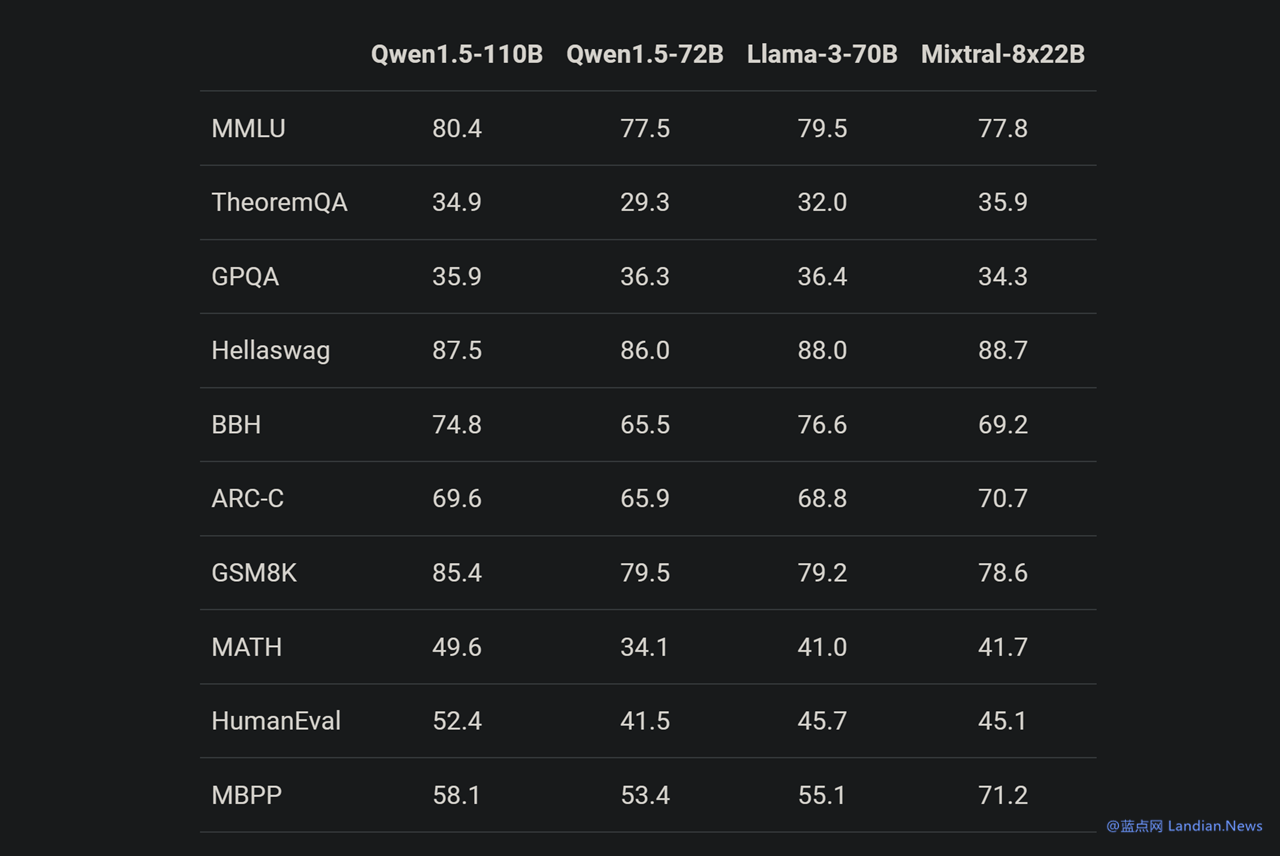
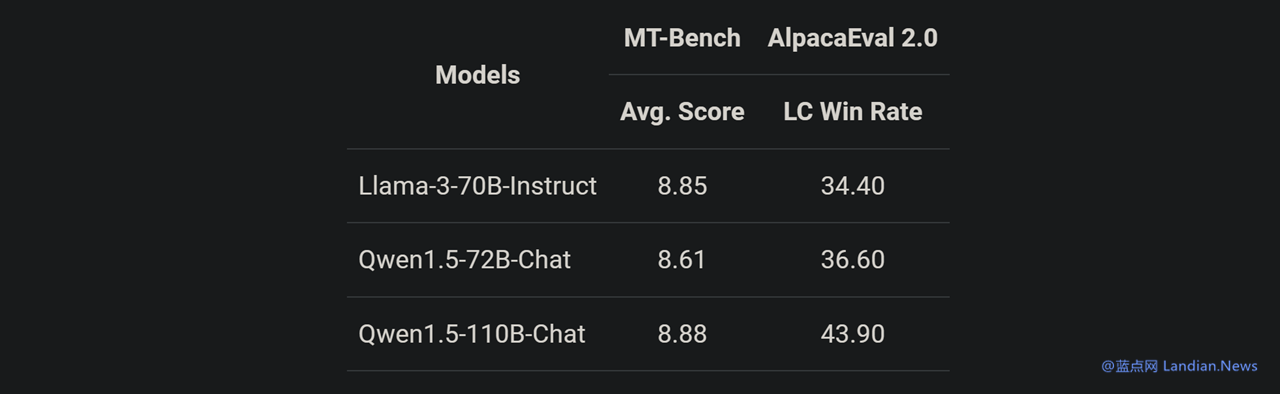
另一项评测似乎也证实这个观点,在与 Llama3-70B-Chat 以及 Qwen1.5-72B-Chat 相比,Qwen1.5-110B-Chat 能力都有提升,这表明在没有大幅度改变预训练方法的状况下,规模更大的基础语言模型也可以带来更好的 Chat 模型。
有兴趣的使用者可以阅读 Qwen1.5 博客知晓该系列模型使用方法,含有 Qwen1.5-110B 的获取和使用等:https://qwenlm.github.io/blog/qwen1.5/
上一篇:《星球大战:赏金猎人》最新上市宣传片公开8月1日发售
下一篇:《Zombie Police:圣诞节与僵尸共舞》将于8月8日发售